Data science has been around for some time. Over the years, data scientists came to recognize the need for a standard methodology and procedures for best practices in data mining and analysis. Combining their knowledge gained from years of experience, they created a well-structured approach to this process. The Cross Industry Standard Process for Data Mining, generally known as CRISP-DM was created as an open standard so as to provide a clear model for analysis. This serves not just as a road map of how to mine and analyze data, but also to increase the possibility of professional collaboration. When an organization uses CRISP-DM, it can help clients understand what standards to expect.
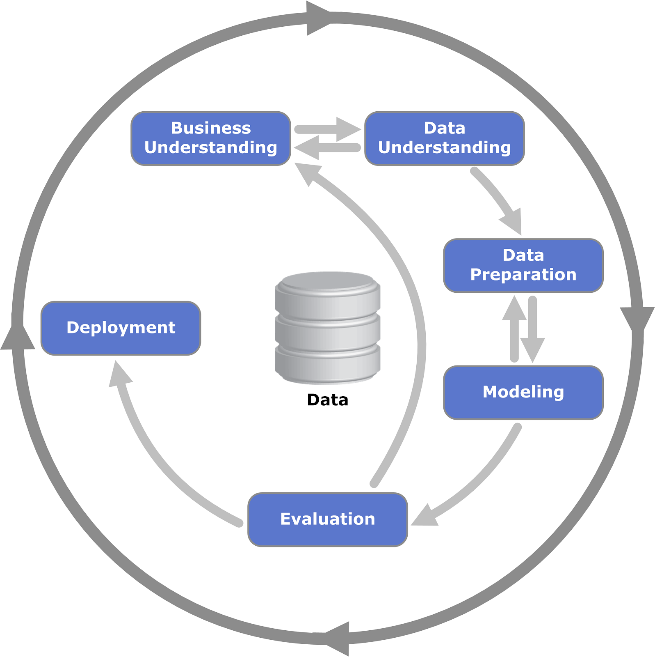
CRISP-DM is a process made up of six different phases. These include Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation and Deployment. These phases are, at a nominal level, approached sequentially, however the process itself is iterative, meaning that any models and understanding are designed to be improved by subsequent knowledge gained throughout the process.
The procedure used within CRISP-DM is demonstrated in the image below Let’s walk through this process from the perspective of analyzing data for a direct marketing organization.