At a high level, Apache Unomi contains the following features:
- User tracking
- Event tracking
- Goal tracking, scoring
- Segmentation
- Form input tracking
- Download tracking
- Personas
- A/B testing
- Privacy Management
- Reporting
- Profile management (includes visitors, contacts, leads, etc)
Use Cases
Let’s take a walk through Apache Unomi to see how it might handle a few use-case type scenarios.
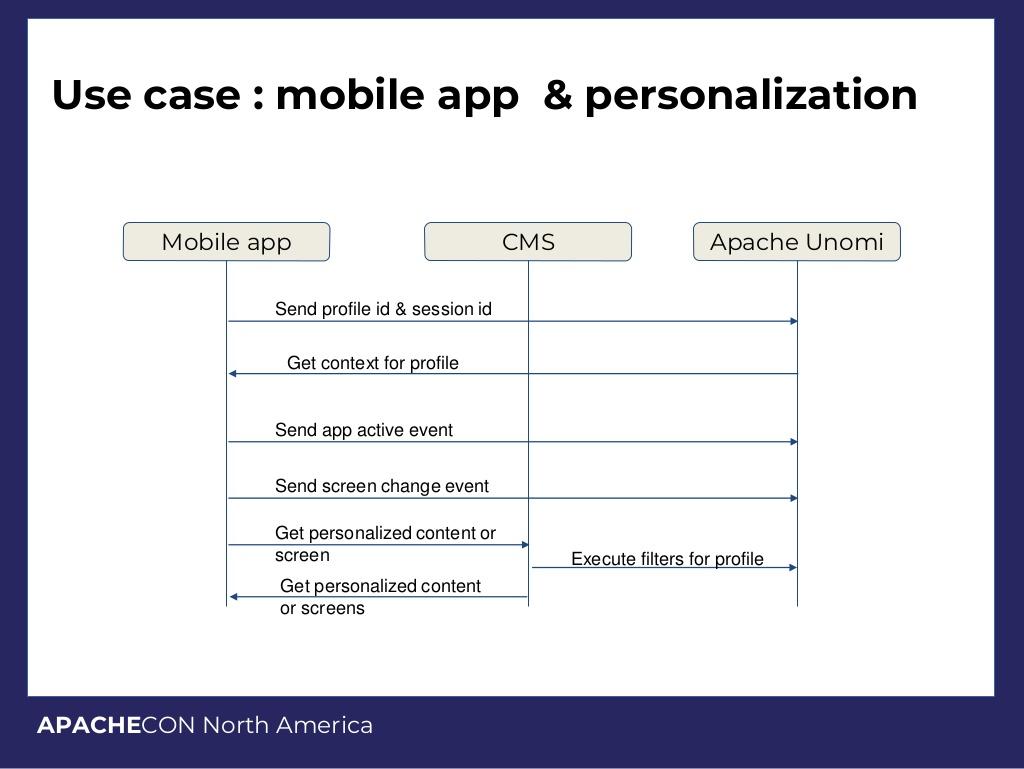
The application can take inputs from a few user-end data sources. These could include visitors to a website, or it could be a mobile user using an application. These external inputs may feed information from the web browser or the mobile app to a content management system (CMS).
This system then gets the HTML and Javascript code and uses this to process the data, and send it all to a context server, which then loads the content into a context json file, which stores all of the information that contextualizes information about the user: who they are, are they the same entity, etc.
At this point, the server then sends back information to assist with the current request. This can include information such as past purchases, browsing history, etc. This information can be then sent back to the CMS. The process can be handled similarly with mobile apps: the data is sent from the app, to the CMS, to UNOMI which then feeds the data back, all the while interacting with the CMS or CRM software.
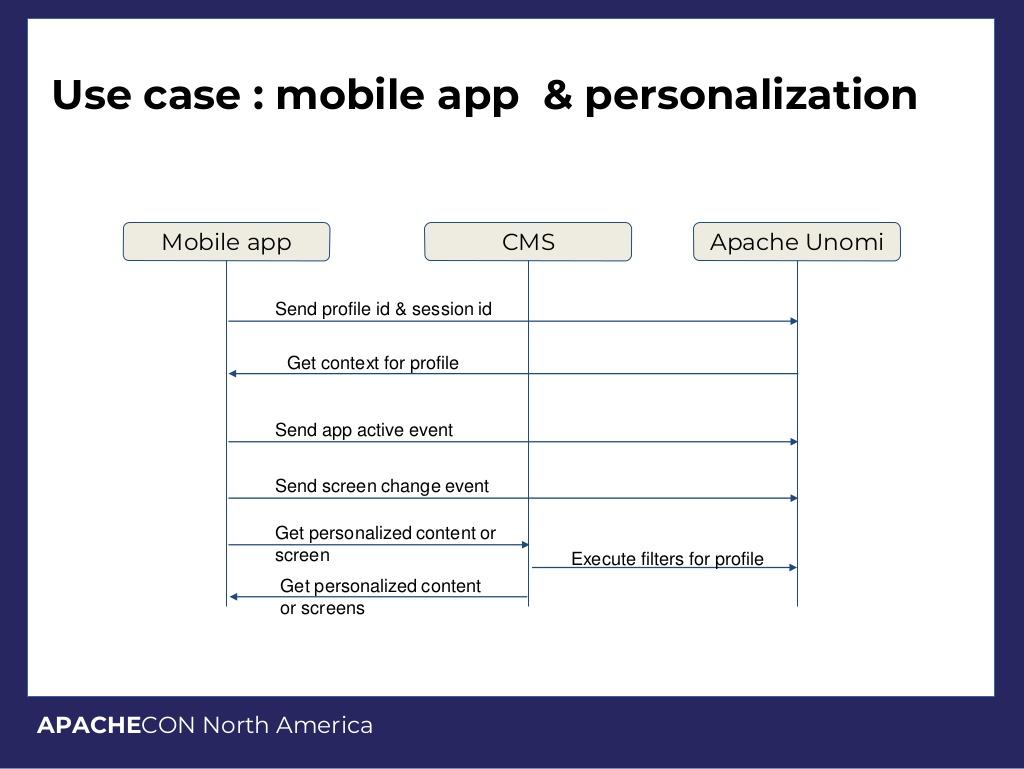
In this way, a full profile of a user gets built, on the fly, and in real time. As a user interacts with a page, that data is then processed by Unomi to provide information to allow the CMS to deliver a customized web page or mobile app for the user.
Let’s break down the Unomi into components.
Profiles
Information about users is built dynamically. Starting with an individually known entity, each behavior and action is recorded into the profile object, which contains known information about who a user is and how they behave
Below is an example of a profile. This is a raw profile prior to any activities or actions occurring. It is a bare skeleton of a user profile.
profile = {
"itemId":"10",
"itemType":"profile",
"version":None,
"properties": {
"firstName": "John",
"lastName": "Smith"
},
"systemProperties":{},
"segments":[],
"scores":{},
"mergedWith":None,
"consents":{}
}
Item
For any data being processed, we need to store the base information, including an identifying id and type of data. For instance, a social media item (a tweet) might look something like this.
{
"itemId": "tweetNb",
"itemType": "propertyType",
"metadata": {
"id": "tweetNb",
"name": "tweetNb",
"systemTags": ["social"]
},
"target": "profiles",
"type": "integer"
}
Event
Events are anything that occurs that can trigger various actions. An event could be an action on a web page or a mobile device, or it could be a weather event or anything else that might impact our data.
Here is a sample event structure
{
"eventType": ,
"scope": ,
"source": ,
"target": ,
"properties":
}
To use a real world -type example, here’s an example page view event:
{
"eventType": "view",
"scope": "ACMESPACE",
"source": {
"itemType": "site",
"scope": "ACMESPACE",
"itemId": "c4761bbf-d85d-432b-8a94-37e866410375"
},
"target": {
"itemType": "page",
"scope": "ACMESPACE",
"itemId": "b6acc7b3-6b9d-4a9f-af98-54800ec13a71",
"properties": {
"pageInfo": {
"pageID": "b6acc7b3-6b9d-4a9f-af98-54800ec13a71",
"pageName": "Home",
"pagePath": "/sites/ACMESPACE/home",
"destinationURL": "http://localhost:8080/sites/ACMESPACE/home.html",
"referringURL": "http://localhost:8080/",
"language": "en"
},
"category": {},
"attributes": {}
}
}
}
Segments
Segments are used for grouping profiles together based on a series of conditions created when an action occurs. We can think of segments as something like target markets. For instance, if we divide users of a social media application as active and non-active, if the user performs any action at all, this person can be placed into a segment called “active users.”
Here’s an example of a sample segment (“leads”) as it is passed through the API and a set of Boolean conditions and sub-conditions that can help determine membership in a segment.
curl -X POST http://localhost:8181/cxs/segments \
--user karaf:karaf \
-H "Content-Type: application/json" \
-d @- <<'EOF'
{
"metadata": {
"id": "leads",
"name": "Leads",
"scope": "systemscope",
"description": "You can customize the list below by editing the leads segment.",
"readOnly":true
},
"condition": {
"type": "booleanCondition",
"parameterValues": {
"operator" : "and",
"subConditions": [
{
"type": "profilePropertyCondition",
"parameterValues": {
"propertyName": "properties.leadAssignedTo",
"comparisonOperator": "exists"
}
}
]
}
}
}
EOF
Conditions
Conditions are what they sound like; they are various identifiers or a list of parameter values for a specific condition. Conditions are set up as trees and are driven by Boolean expressions.
They can be simple, or they can have many complex determinants to identify very specific segments. Here’s a sample complex condition
{
"condition": {
"type": "booleanCondition",
"parameterValues": {
"operator":"or",
"subConditions":[
{
"type": "eventTypeCondition",
"parameterValues": {
"eventTypeId": "sessionCreated"
}
},
{
"type": "eventTypeCondition",
"parameterValues": {
"eventTypeId": "sessionReassigned"
}
}
]
}
}
}
Privacy Features
As mentioned earlier, one of the unique features of Unomi is its ability to handle consumer privacy. It has a series of features to make it possible for applications to be fully GDPR compliant.
Apache Unomi contains the following privacy/identity management features
- Profile Properties management
- “personal identifier” properties
- Endpoint anonymizing (which can erase the identifier above)
- Consent management
- Privacy management
- Downloadable profiles for users
The consent management module is a separate API, which contains a scope, the type identifier for the consent, a status (grant, deny, revoke), the date, and the revocation date.
Example profile with a consent attached
{
"profileId": "18afb5e3-48cf-4f8b-96c4-854cfaadf889",
"sessionId": "1234",
"profileProperties": null,
"sessionProperties": null,
"profileSegments": null,
"filteringResults": null,
"personalizations": null,
"trackedConditions": [],
"anonymousBrowsing": false,
"consents": {
"example/newsletter": {
"scope": "example",
"typeIdentifier": "newsletter",
"status": "GRANTED",
"statusDate": "2018-05-22T09:27:09Z",
"revokeDate": "2020-05-21T09:27:09Z"
}
}
}
Rules
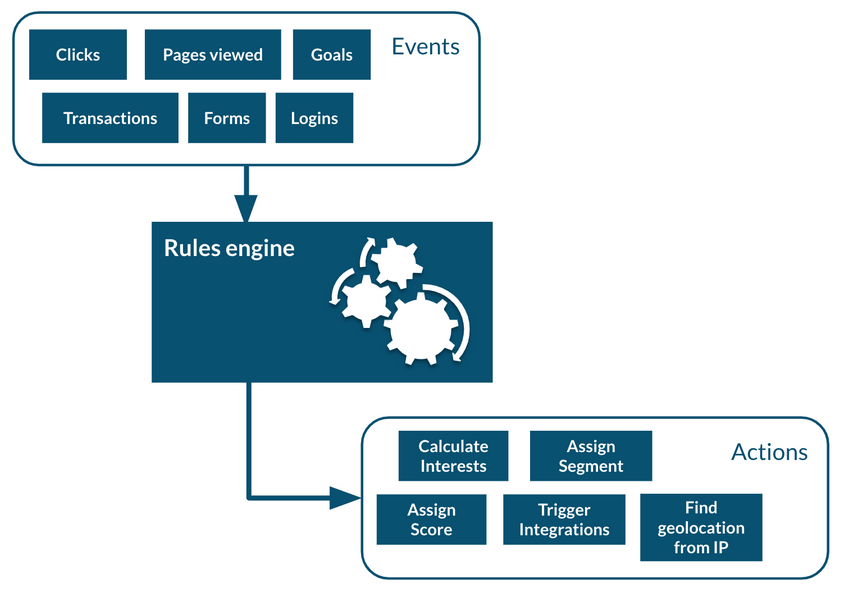
The rule engine operates in real time and can quickly generate this data at the moment a user performs an event, or an action occurs. Safety/privacy also works in real time. As it checks for information from trusted third parties, various rules become defined and are recorded in the user’s profile.
Actions occur when rules are satisfied, or conditions are met and will perform any create, read, update, or delete (CRUD) function defined.
The below diagram demonstrates how the process works. For example, we can retrieve data from a form event, copy it into the user profile, update profile segments, and send updated profile to a salesforce account.
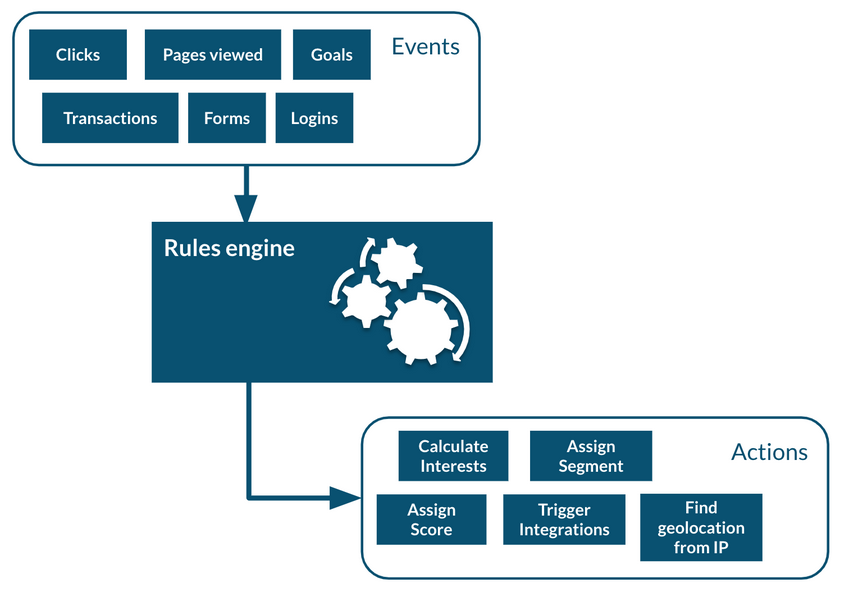
Data will merge in real time with other pre-existing data.
If we are to build this out, let’s take an example persona. Let’s say we want to identify the characteristics of a user that would make her a middle classed woman under the age of thirty.
We can create an example persona defined by income between 40K and 100K AND age <30
Let’s also say that she is an active user of a site and is interested in sports. This person could be identified as having read 10 or more pages with a tag labeled “sports” and has had at least 10 sessions within the last 10 days.

Performance and Scalability
Apache Unomi is built for scalability. It is built on top of the Apache Karaf runtime environment, and uses ElasticSearch clustering. Unomi is easily extensible to help remove any bottlenecks caused during the data ingestion process or by rule processing. This can be handled by adding new nodes. The nature of the Karaf environment means that this will have little impact on processing speed.
Services
Apache Unomi provides the following services inside the Karaf cluster:
- Shell commands
- Segment services
- Salesforce actions
- Mailchimp actions
- Weather
- Rule engine
- Profile service
- Query service
- Goals service
- Personalization service
- Event service
- Segment (market) service
- Definitions (rules, actions)
These are sent through the ElasticSearch Cluster.