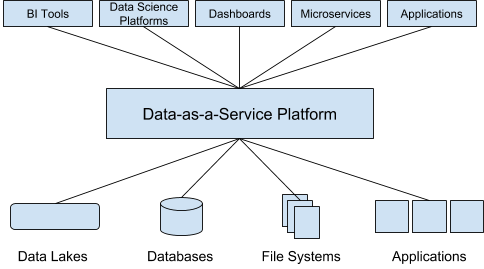
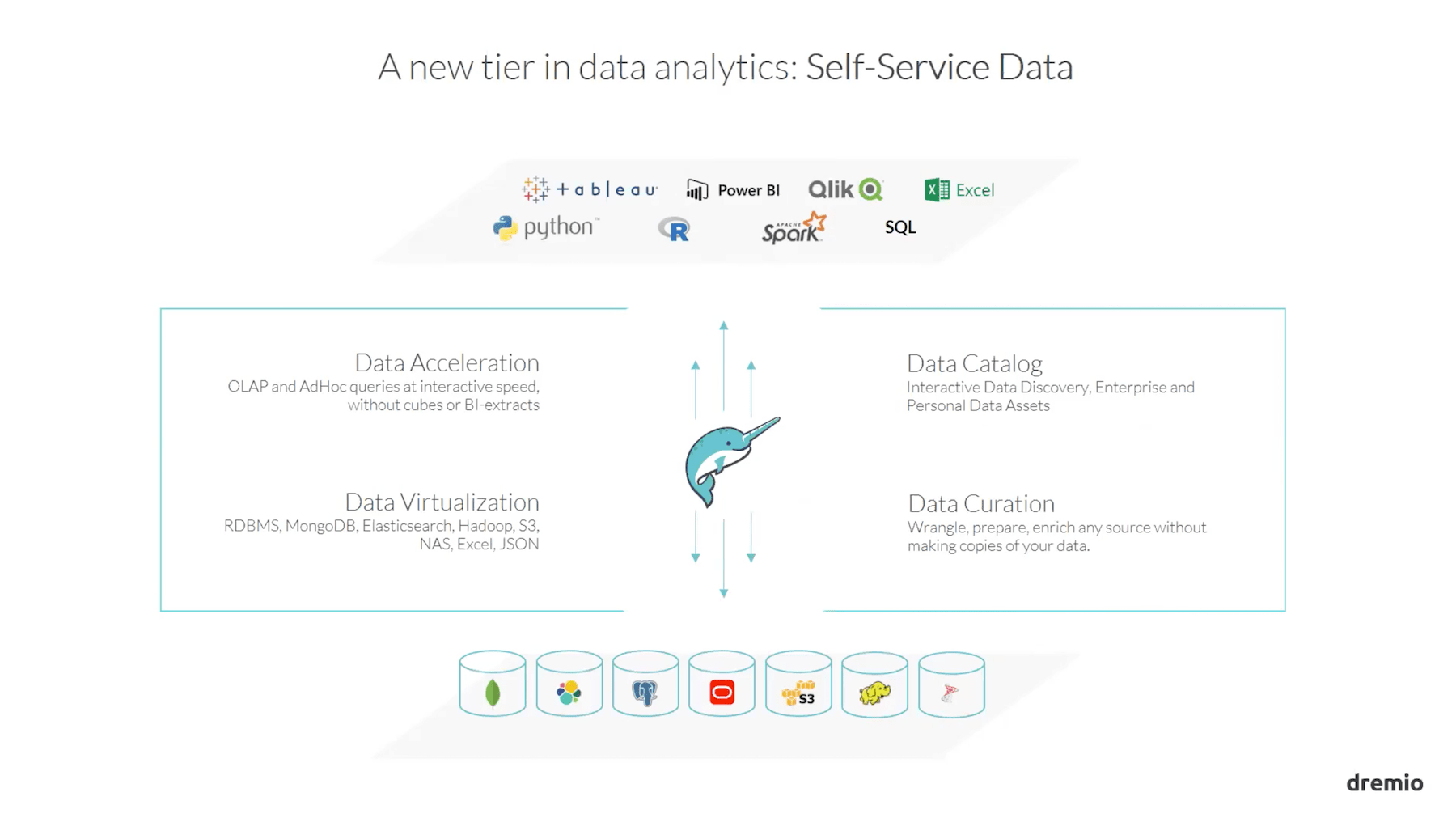
Data Extraction
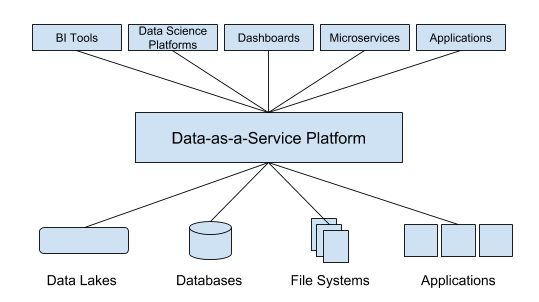
Dremio is a self-service data ingestion tool. Although data extraction is a basic feature of any DAAS tool, most DAAS tools require custom scripts for different data sources. Dremio has a different approach for data extraction. Dremio creates a central data catalog for all the data sources you connect to it. With that, anyone can access and explore any data any time, regardless of structure, volume or location. No matter how you store your data, Dremio makes it work like a standard relational database. Furthermore, you don’t have to build data pipelines when a new data source comes online. Dremio gives you instant access.
Rapid Processing of Data
The Data Reflection feature of Dremio makes it one of the fastest data processing systems. The system automatically accelerates data and queries up to 1000x faster leveraging the full power of relational algebra. Dremio has a vertically integrated Query Engine that automatically generates query planes to make the best use of Data Reflection. Another important feature of Dremio is its Native Push Downs which result in query optimization for every data source. In other words, you have a query language which is optimized for Amazon S3, HDFS, NoSQL, RDBMS, ADLS independently. Last but not least, Dremio uses Apache Arrow and Apache Parquet to utilize high-performance columnar storage and execution as opposed to normal row based databases. In simple terms, this means lightning fast performance on very large data sets.

The Ability to Scale
Dremio facilitates automatic scaling from one server to thousands of servers in one cluster if needed. You can easily integrate new data sources as well within the cluster. Dremio can handle very large data sets and heavy workloads.
Data Visualization
Data visualization is the easiest way to get meaningful insight from your data. Visualization enables data to be more human readable. For example, different types of graphs available in Dremio will display data in a format easier to interpret. Dremio functions as the data visualization pipeline. With Dremio, you don’t have to do complex manipulation of data by writing complex SQL queries or complex code. It does joining, filtering or processing of data for you.
Dremio charts interpret data in a more human-readable form.
Support Different Data Sources
There is a long list of data sources that Dremio supports. Most simply, you can upload a CSV file, Excel sheet, or delimited file from your local computer. After that, you simply join with Dremio data sources before querying or using any BI tool. Alternatively, Dremio supports many third-party data sources such as Amazon Redshift, Amazon S3, Amazon Elasticsearch, Azure Data Lake Store, Elasticsearch, HDFS, Hive, MapR-FS, Microsoft SQL Server, MongoDB, MySQL, NAS, Oracle, Postgres and others.
Advanced Security
Data breaching is the most common form of cybercrime. Analytical systems are a natural target. Therefore, the value of a high-security architecture for a product like Dremio can’t be emphasized enough. Dremio has taken many steps to protect users from possible threats.
Authentication and authorization play the biggest role in any security architecture. Dremio uses a FIPS 140-2 compliant cryptographic algorithm to manage user credentials in internal user authentication and supports secret and key rotation. Certificates can be updated by using the Java Keystore tool.
Deployment
Dremio can be deployed on-premises or in a public cloud. There are three deployment patterns commonly used:
- Using dedicated infrastructures such as EC2 instances
- Using docker containers with Kubernetes for provisioning and management
- Using Hadoop as a Yarn application
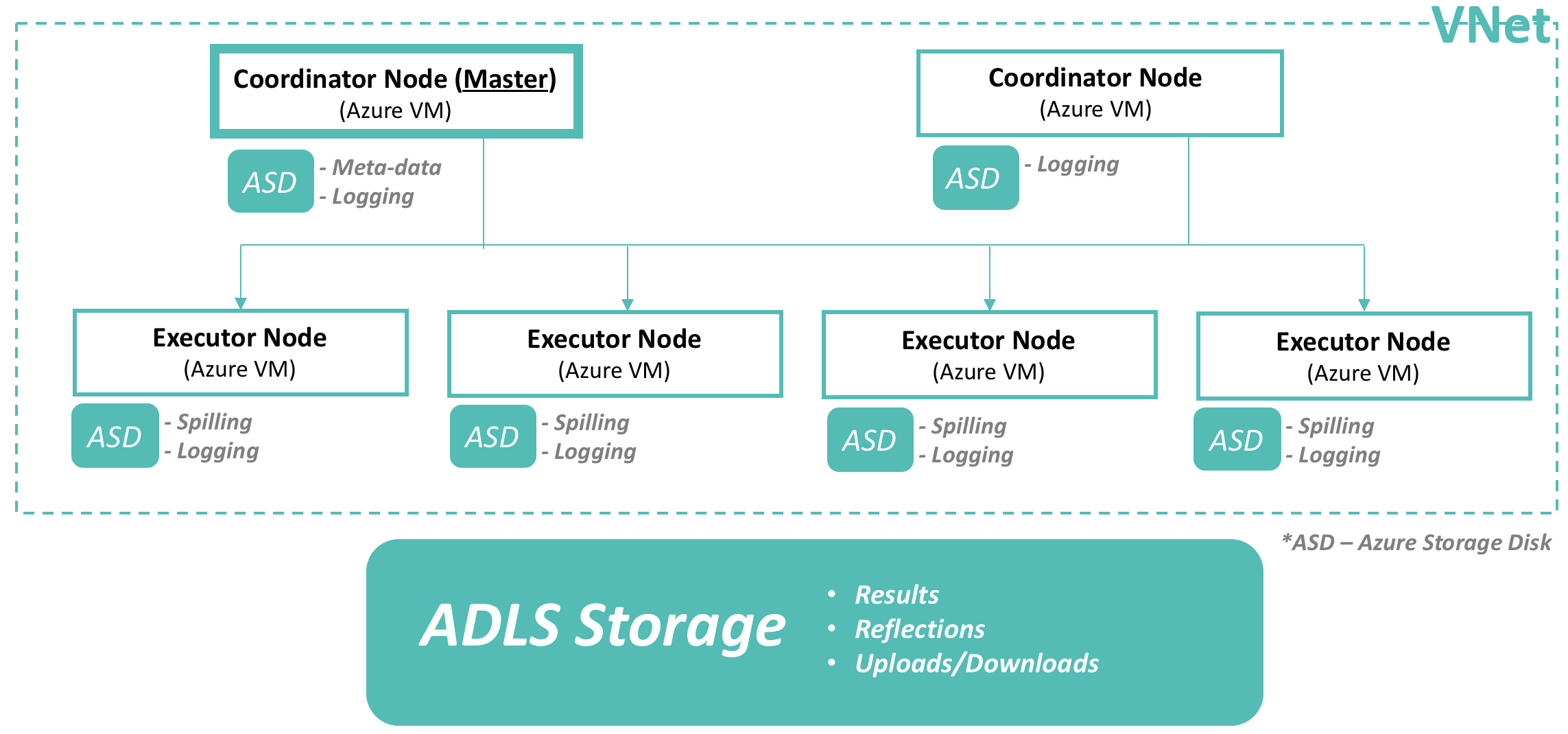
It is recommended to use Dremio on dedicated hardware as it will allow Dremio to use the local filesystem for persisting reflections. For example, for AWS deployments, S3 is supported for persisting reflections, which provides cost-effective reliability without sacrificing performance
Note that your deployment plan should consider the following factors as well.
- Hardware
- Size
- High Availability
- Back up and recovery.
Diagram of Dremio Deployment in Azure VM